A versão 12c do Oracle já está aí há um bom tempo, e eu até já escrevi alguns artigos a respeito, porém acredito que um dos principais eu não tenham produzido até então, mas chegou a hora de fazê-lo, enfim vamos lá falar da instalação do Oracle 12c, em ambiente Linux é claro!
Preparando o sistema operacional:
A primeira etapa deste processo consistem em preparar o sistema operacional para que se possa instalar o Oracle, sendo assim, precisamos fazer alguns ajustes dentro do Linux. Há duas formas de fazê-lo, uma é de maneira automática, onde você simplesmente baixa uma lib do “public-yum” da Oracle e essa lib faz tudo pra você e outra onde se faz tudo manualmente (aliás eu recomendo essa maneira para os iniciantes, é mais difícil, porém você vai praticar mais e aprender mais). Aqui veremos as duas maneiras.
Porém antes dessa etapa precisamos acertar um pequeno detalhe no servidor, que é a resolução do hostname, vamos lá.
Com algum editor de texto, abra o arquivo “/etc/hosts” e faça com que ele resolva o hostname de seu servidor, conforme abaixo.
<IP-address> <fully-qualified-machine-name> <machine-name>
Exemplo:
127.0.0.1 localhost.localdomain localhost
192.168.0.210 oradata-lab1.localdomain oradata-lab1
Instalando os pré-requisitos de SO (automático).
Para acertar as configurações do seu SO de maneira automática, basta configurar o “plublic-yum” (se não souber acesse http://public-yum.oracle.com) em seu servidor e baixar a lib “oracle-rdbms-server-12cR1-preinstall”.
# yum install oracle-rdbms-server-12cR1-preinstall -y
Após terminar essa etapa, você pode seguir para as configurações adicionais e na sequencia o “setup” propriamente do software do Oracle.
Instalando os pré-requisitos de SO (automático).
Caso opte pela configuração manual do SO, você deve seguir os seguintes passos:
Adicione as seguintes entradas no “/etc/sysctl.conf”
fs.file-max = 6815744
kernel.sem = 250 32000 100 128
kernel.shmmni = 4096
kernel.shmall = 1073741824
kernel.shmmax = 4398046511104
net.core.rmem_default = 262144
net.core.rmem_max = 4194304
net.core.wmem_default = 262144
net.core.wmem_max = 1048576
fs.aio-max-nr = 1048576
net.ipv4.ip_local_port_range = 9000 65500
Na sequência, execute o commando “/sbin/sysctl –p”
/sbin/sysctl -p
Adicione as seguintes linhas no arquivo “/etc/security/limits.conf.
oracle soft nofile 1024
oracle hard nofile 65536
oracle soft nproc 16384
oracle hard nproc 16384
oracle soft stack 10240
oracle hard stack 32768
Para que a instalação do Oracle funcione corretamente, as seguintes “libs” precisam ser instaladas:
yum install binutils -y
yum install compat-libcap1 -y
yum install compat-libstdc++-33 -y
yum install compat-libstdc++-33.i686 -y
yum install gcc -y
yum install gcc-c++ -y
yum install glibc -y
yum install glibc.i686 -y
yum install glibc-devel -y
yum install glibc-devel.i686 -y
yum install ksh -y
yum install libgcc -y
yum install libgcc.i686 -y
yum install libstdc++ -y
yum install libstdc++.i686 -y
yum install libstdc++-devel -y
yum install libstdc++-devel.i686 -y
yum install libaio -y
yum install libaio.i686 -y
yum install libaio-devel -y
yum install libaio-devel.i686 -y
yum install libXext -y
yum install libXext.i686 -y
yum install libXtst -y
yum install libXtst.i686 -y
yum install libX11 -y
yum install libX11.i686 -y
yum install libXau -y
yum install libXau.i686 -y
yum install libxcb -y
yum install libxcb.i686 -y
yum install libXi -y
yum install libXi.i686 -y
yum install make -y
yum install sysstat -y
yum install unixODBC -y
yum install unixODBC-devel -y
Crie os grupos “oinstall” e “db” e na sequencia crie o usuário “oracle”.
groupadd -g 54321 oinstall
groupadd -g 54322 dba
useradd -g oinstall -G dba oracle
Para efeitos de testes, defina o nivel de segurança do “SELINUX” como permissive, lembrando, apenas para laboratórios, não use isso em produção. No arquivo “/etc/selinux/config”
SELINUX=permissive
Após a alteração, execute o comando como “root”
setenforce Permissive
Desabilite o firewall do Linux.
service iptables stop
chkconfig iptables off
Crie os diretórios para a instalação do software.
mkdir -p /u01/app/oracle/product/12.1.0.2/dbhome_1
chown -R oracle:oinstall /u01
chmod -R 775 /u01
Acerte as variáveis de ambiente no “/home/oracle/.bash_profile”.
# Oracle Settings
export TMP=/tmp
export TMPDIR=$TMP
export ORACLE_HOSTNAME=ol6-121.localdomain
export ORACLE_UNQNAME=cdb1
export ORACLE_BASE=/u01/app/oracle
export ORACLE_HOME=$ORACLE_BASE/product/12.1.0.2/db_1
export ORACLE_SID=cdb1
export PATH=/usr/sbin:$PATH
export PATH=$ORACLE_HOME/bin:$PATH
export LD_LIBRARY_PATH=$ORACLE_HOME/lib:/lib:/usr/lib
export CLASSPATH=$ORACLE_HOME/jlib:$ORACLE_HOME/rdbms/jlib
Descompacte os arquivos de instalação.
unzip linuxamd64_12102_database_1of2.zip
unzip linuxamd64_12102_database_2of2.zip
Acesse a pasta “database” e execute o arquivo de instalação do software “./runInstaller”.
./runInstaller
Na primeira tela, desmarque as opções para baixar atualizações automáticas do “My Oracle Support”.
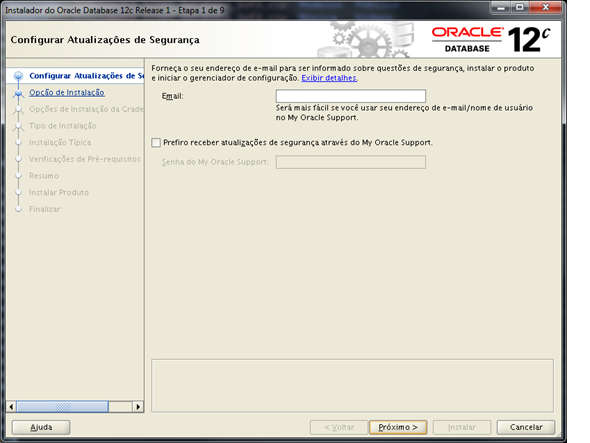
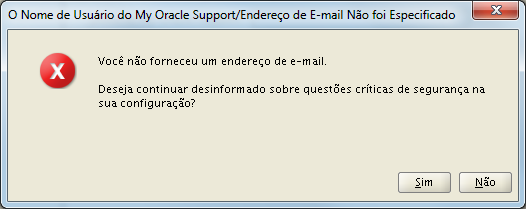
Confirme as opção novamente, clicando em “Sim”.
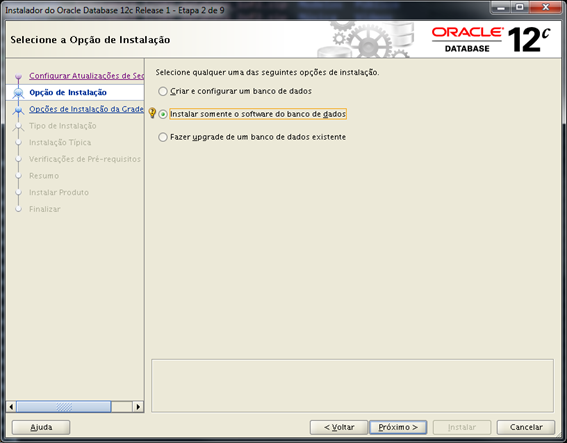
Selecione a opção “Instalar somente o software do banco de dados”.
Marque a opção “Instalação do banco de dados de instancia única”.

Nas opção de idiomas, selecione o que melhor lhe atender (preferencialmente “Português do Brasil” ou “Inglês”).

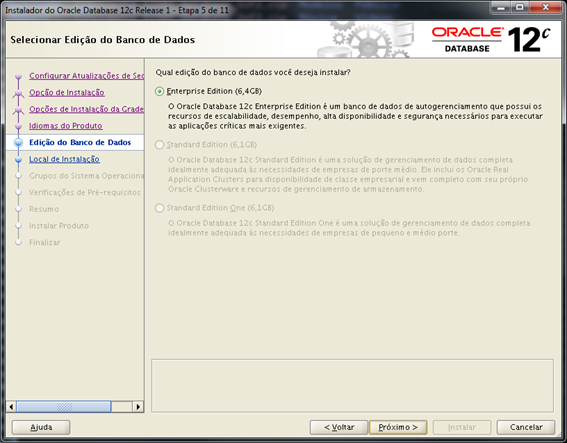
Selecione a edição do banco de dados que deseja usar (Enterprise, Standard ou Standard Edition).
Verifique se os caminhos apresentados para $ORACLE_BASE e $ORACLE_HOME estão compatíveis com o que você definiu no “.bash_profile”.
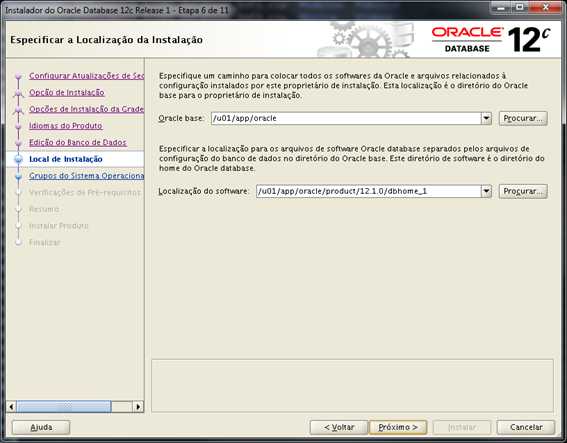
Verifique as definições de nomes de usuário e grupos dentro do sistema operacional.

Aguarde a verificação dos pré-requisitos. Caso haja alguma coisa pendente o instalador irá reportar a falha, mas estando tudo certo, a próxima tela será apenas para rever as opções da instalação.

Reveja as informações da instalação que você vai fazer e clique em “Instalar”.
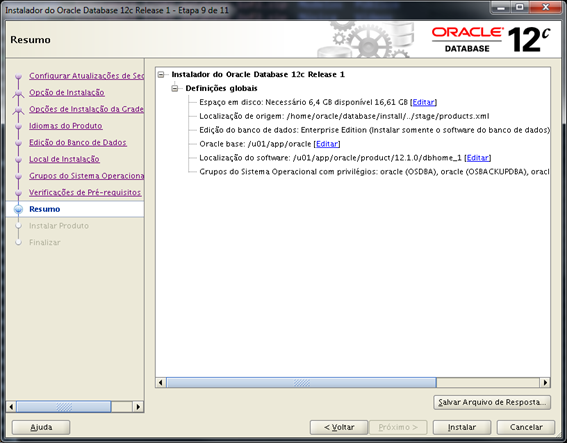
Acompanhe o processo de instalação. Até que lhe seja solicitado a execução dos scripts como “root”.

Execute o script a seguir logado com o usuário “root”.
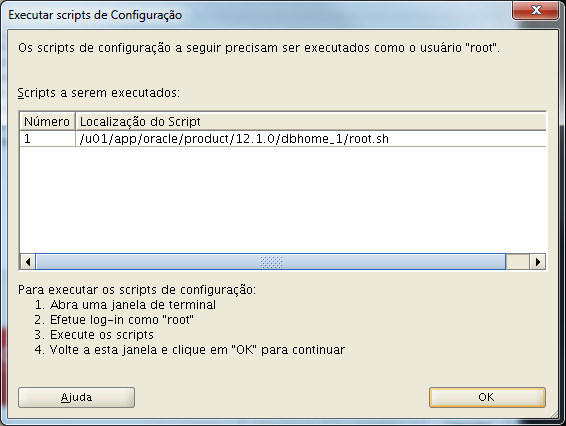
Pronto! Seu software está instalado, o próximo passo agora é criar a base de dados, em breve escreverei um artigo relacionado.
Forte abraço!
Douglas Paiva de Sousa























{kind=link}
{kind=link}
{kind=link}